@misc{zhan2026seamsmoothexecutionactionchunked,title={SEAM: Smooth Execution of Action-Chunked Motion for Vision-Language-Action Policies},author={Zhan*, Dijia and Xu†, Xuemiao and Li*, Jinyi and Tang†, Jie},year={2026},eprint={2607.04609},archiveprefix={arXiv},primaryclass={cs.RO},url={https://arxiv.org/abs/2607.04609},annotation={* Equal Contribution<br>† Corresponding authors},}
NavOne: One-Step Global Planning for Vision-Language Navigation on Top-Down Maps
Dijia Zhan* , Jinyi Li*, Chenxi Zheng, Shaoyu Huang, Yong Li†, Jie Tang†, and Xuemiao Xu†
arXiv preprint arXiv:2605.06317. More Information can be found on official website , 2026
Existing Vision-Language Navigation (VLN) methods typically adopt an egocentric, step-by-step paradigm, which struggles with error accumulation and limits efficiency. While recent approaches attempt to leverage pre-built environment maps, they often rely on incrementally updating memory graphs or scoring discrete path proposals, which restricts continuous spatial reasoning and creates discrete bottlenecks. We propose Top-Down VLN (TD-VLN), reformulating navigation as a one-step global path planning problem on pre-built top-down maps, supported by our newly constructed R2R-TopDown dataset. To solve this, we introduce NavOne, a unified framework that directly predicts dense path probabilities over multi-modal maps in a single end-to-end forward pass. NavOne features a Top-Down Map Fuser for joint multi-modal map representation, and extends Attention Residuals for spatial-aware depth mixing. Extensive experiments on R2R-TopDown show that NavOne achieves state-of-the-art performance among map-based VLN methods, with a planning-stage speedup of 8x over existing map-based baselines and 80x over egocentric methods, enabling highly efficient global navigation.
@article{zhan2026navone,title={NavOne: One-Step Global Planning for Vision-Language Navigation on Top-Down Maps},author={Zhan*, Dijia and Li*, Jinyi and Zheng, Chenxi and Huang, Shaoyu and Li†, Yong and Tang†, Jie and Xu†, Xuemiao},journal={arXiv preprint arXiv:2605.06317},year={2026},archiveprefix={arXiv},primaryclass={cs.CV},google_scholar_id={2osOgNQ5qMEC},annotation={* Equal Contribution<br>† Corresponding authors},additional_info={. *More Information* can be found on [official website](https://altman-conquer.github.io/NavOnePage/)},}
2025
Seeing 3D Through 2D Lenses: 3D Few-Shot Class-Incremental Learning via Cross-Modal Geometric Rectification
@inproceedings{xiang2025seeing3d2dlenses,title={Seeing 3D Through 2D Lenses: 3D Few-Shot Class-Incremental Learning via Cross-Modal Geometric Rectification},author={Xiang, Tuo and Xu, Xuemiao and Liu†, Bangzhen and Li, Jinyi and Li†, Yong and He, Shengfeng},year={2025},eprint={2509.14958},archiveprefix={arXiv},primaryclass={cs.CV},url={https://arxiv.org/abs/2509.14958},google_scholar_id={9yKSN-GCB0IC},booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},pages={6761--6771},annotation={† Corresponding authors},}
PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models
Zheng Zhang , Jinyi Li, Yihuai Lan , Xiang Wang, and Hao Wang†
Prompt engineering enables Large Language Models (LLMs) to perform a variety of tasks. However, lengthy prompts significantly increase computational complexity and economic costs. To address this issue, we study six prompt compression methods for LLMs, aiming to reduce prompt length while maintaining LLM response quality. In this paper, we present a comprehensive analysis covering aspects such as generation performance, model hallucinations, efficacy in multimodal tasks, word omission analysis, and more. We evaluate these methods across 13 datasets, including news, scientific articles, commonsense QA, math QA, long-context QA, and VQA datasets. Our experiments reveal that prompt compression has a greater impact on LLM performance in long contexts compared to short ones. In the Longbench evaluation, moderate compression even enhances LLM performance.
@inproceedings{zheng2025empirical,title={An Empirical Study on Prompt Compression for Large Language Models},author={Zheng, Zhang and Li, Jinyi and Lan, Yihuai and Wang, Xiang and Wang†, Hao},booktitle={ICLR 2025 Workshop on Building Trust in Language Models and Applications},year={2025},eprint={2505.00019},archiveprefix={arXiv},primaryclass={cs.CL},google_scholar_id={u-x6o8ySG0sC},doi={10.48550/arXiv.2505.00019},annotation={† Corresponding authors},}
2024
PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models
Prompt compression is an innovative method for efficiently condensing input prompts while preserving essential information. To facilitate quick-start services, user-friendly interfaces, and compatibility with common datasets and metrics, we present the Prompt Compression Toolkit (PCToolkit). This toolkit is a unified plug-and-play solution for compressing prompts in Large Language Models (LLMs), featuring cutting-edge prompt compressors, diverse datasets, and metrics for comprehensive performance evaluation. PCToolkit boasts a modular design, allowing for easy integration of new datasets and metrics through portable and user-friendly interfaces. In this paper, we outline the key components and functionalities of PCToolkit. We conducted evaluations of the compressors within PCToolkit across various natural language tasks, including reconstruction, summarization, mathematical problem-solving, question answering, few-shot learning, synthetic tasks, code completion, boolean expressions, multiple choice questions, and lies recognition.
@misc{li2024pctoolkit,title={PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models},author={Li, Jinyi and Lan, Yihuai and Wang, Lei and Wang†, Hao},year={2024},eprint={2403.17411},archiveprefix={arXiv},primaryclass={cs.CL},google_scholar_id={u5HHmVD_uO8C},doi={10.48550/arXiv.2403.17411},dimensions={true},annotation={† Corresponding authors},}
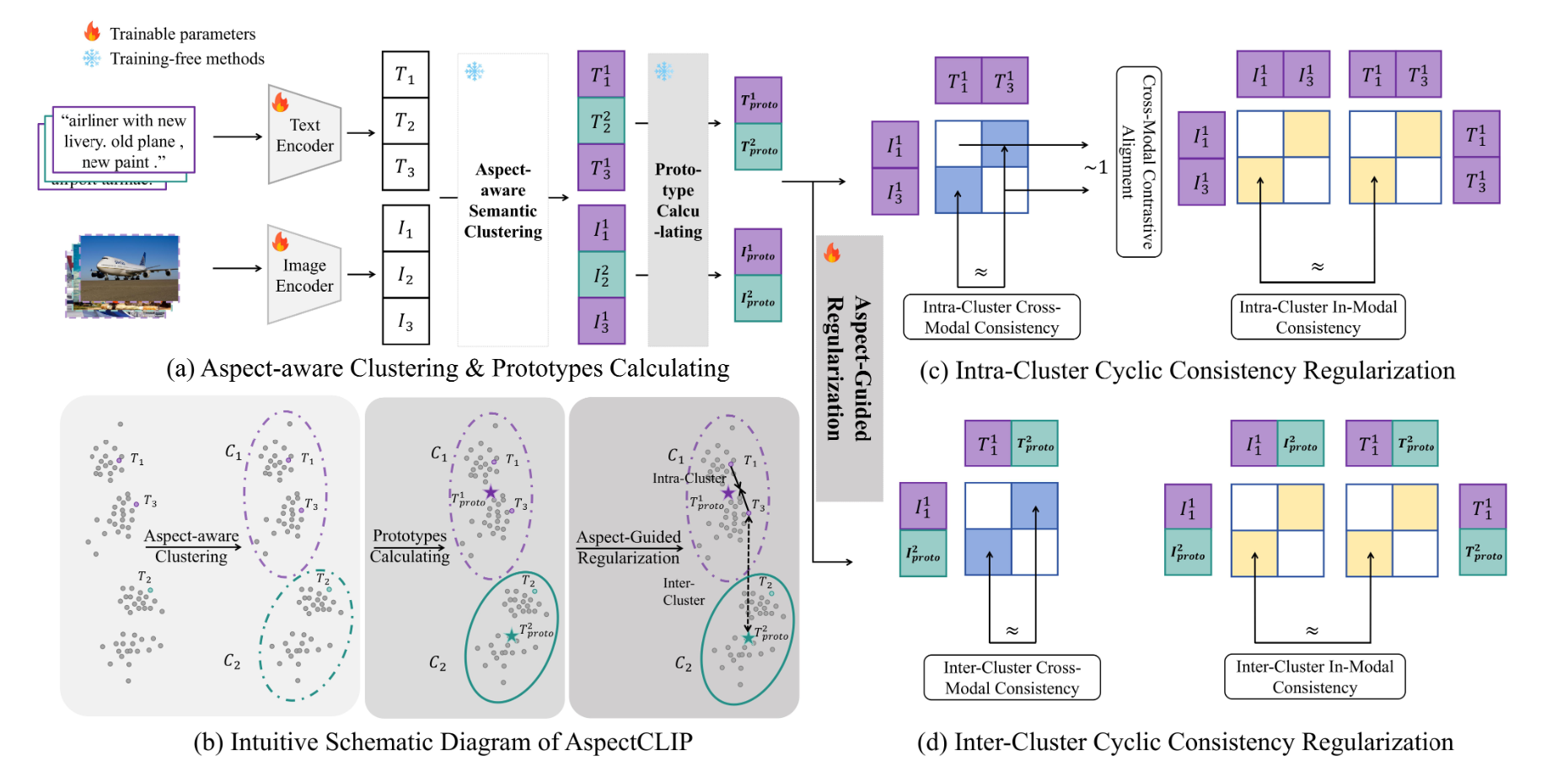 AspectCLIP: Optimizing CLIP Representation Space via Aspect-Guided Consistency Regularization2026
AspectCLIP: Optimizing CLIP Representation Space via Aspect-Guided Consistency Regularization2026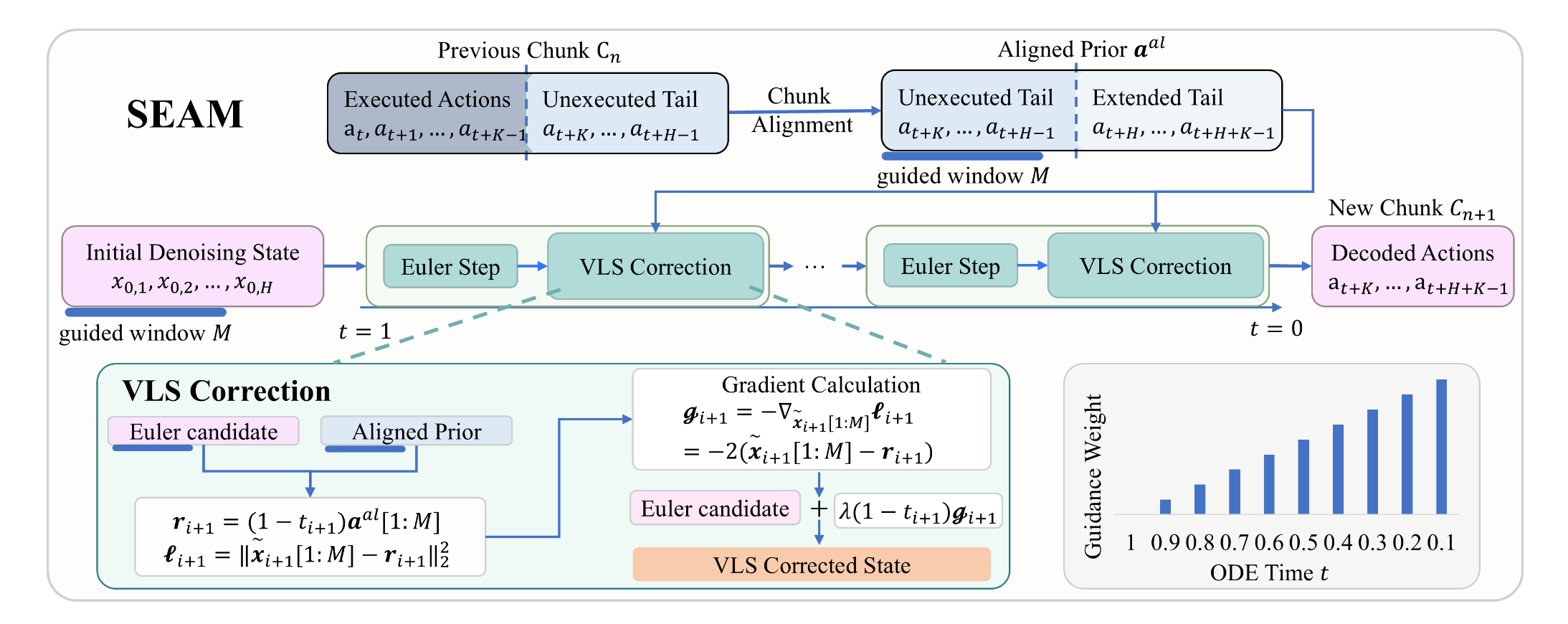
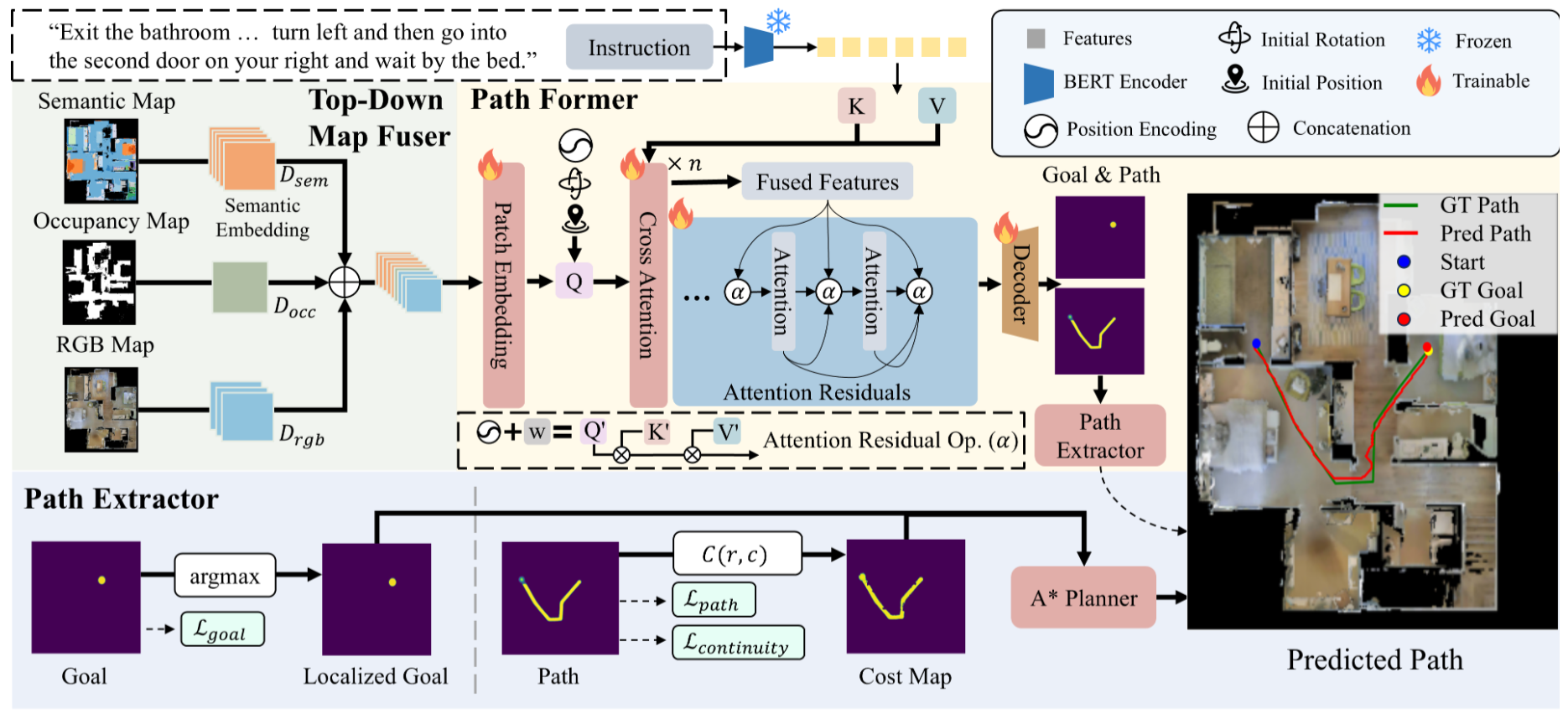 NavOne: One-Step Global Planning for Vision-Language Navigation on Top-Down MapsarXiv preprint arXiv:2605.06317. More Information can be found on official website , 2026
NavOne: One-Step Global Planning for Vision-Language Navigation on Top-Down MapsarXiv preprint arXiv:2605.06317. More Information can be found on official website , 2026


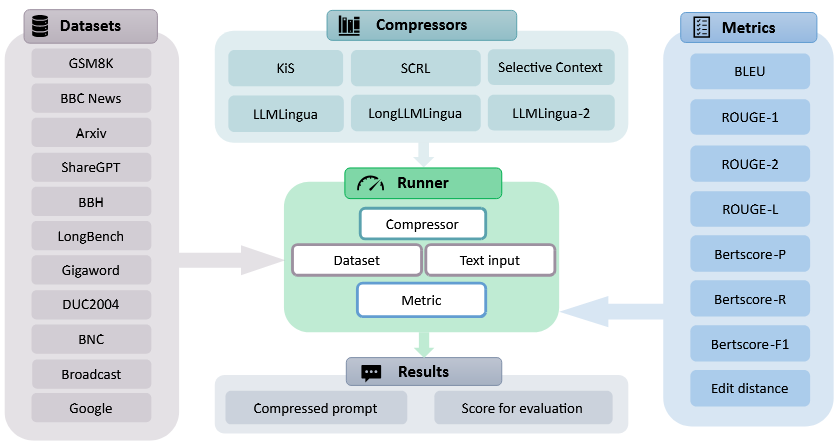 PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language ModelsIn IJCAI 2025 Demonstration Track , 2025
PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language ModelsIn IJCAI 2025 Demonstration Track , 2025

